今天凌晨两点多被朋友圈炸醒,小米悄咪咪把MiMo Code V0.1.0开源了,用的还是最宽松的MIT协议。我当时直接从床上爬起来,对着终端敲了一行curl命令,三分钟就装好了,连注册登录都不用,打开直接用。
说真的,这玩意儿比我想象中好用太多。以前用别的AI编程助手,写个长点的项目,聊个几十轮就开始失忆,明明刚才说过的需求转头就忘,得反复提醒。MiMo Code那个持久记忆系统真的解决了这个痛点,它有个后台子Agent专门负责存状态,窗口快满了就自动压缩成简报,主Agent接着干,完全不卡壳。我今天上午用它写了个简单的后台接口,前后聊了一百多轮,它连我最开始提的"要加个日志中间件"都记得清清楚楚。
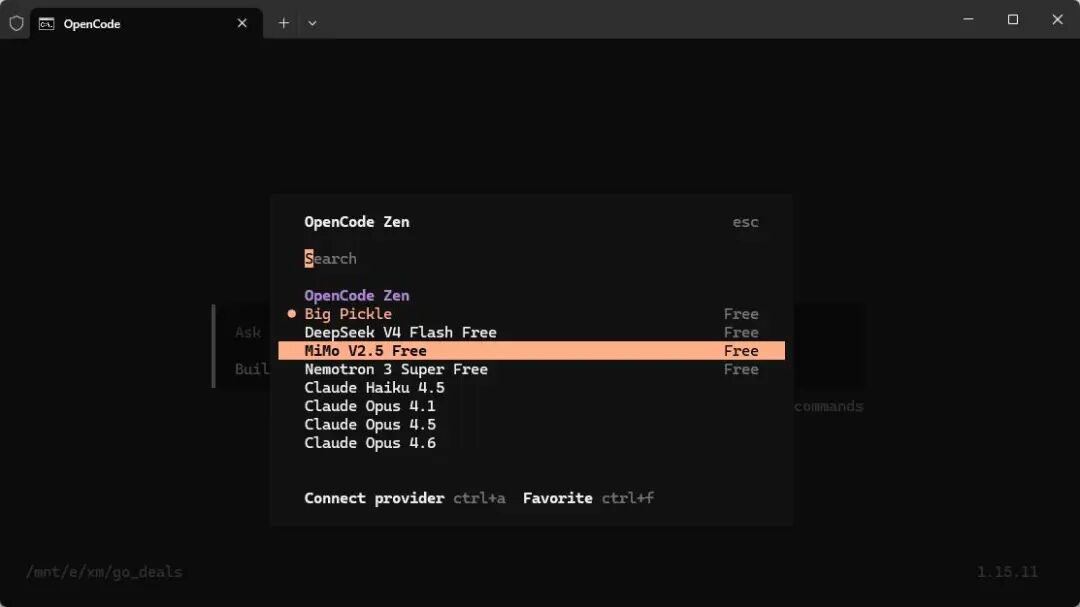
而且它不锁模型,内置的MiMo-V2.5现在限时免费,不够用还能自己接DeepSeek、Kimi这些,甚至可以用自己本地跑的模型。SWE-Bench Pro上比Claude Code还高5分,我实测写爬虫和前端组件确实更快,注释也写得很规范,还能自动帮我跑单元测试。
然后是前两天炸圈的MiMo-V2.5-Pro-UltraSpeed,也就是大家说的MiMo Ultra。雷军那条微博我看了不下十遍,在通用GPU上把万亿参数模型干到1000 tokens/s,峰值1200,这真的是跨时代的突破。

给你们算个账,GPT-5.5大概68 tokens/s,Claude Opus71,最快的Gemini Flash也就192,小米这个直接快了一个数量级。官方演示里10秒写一个贪吃蛇,13秒生成一个完整的AI运营大屏,标准版要6分15秒,提速了28倍。我有个做算法的朋友拿到了测试资格,他说现在写代码根本不用等,刚说完需求,代码已经输出完了,那种感觉就像AI在跟你同步思考。
当然槽点也很明显。UltraSpeed现在是申请制,从6月9号到23号,每天只能排队10次,单次会话最多30分钟,闲置5分钟就自动踢下线。我昨天申请了到现在还没通过,看群里说优先给企业和专业开发者,普通用户基本没戏。价格是标准版的3倍,但速度快了10倍,算下来其实性价比更高,就是资源太紧张了。
还有人说这是小米在炫技,但我觉得意义远不止于此。以前大模型都是拼参数量、拼榜单分数,现在终于开始拼实际能用的速度了。1000 tokens/s意味着万亿参数模型能进入实时决策场景了,以后AI炒股、实时风控、手术辅助这些以前不敢想的事,现在都有可能实现。
而且最关键的是,小米没用什么定制芯片,就是用市面上能买到的普通8卡GPU服务器,靠模型和系统的协同优化做到的。这就意味着这个技术是可复制、可普及的,以后其他厂商也能跟着学,整个行业的推理速度都会提上来。
今天一天我都在折腾MiMo Code,真的有种未来已来的感觉。以前觉得AI还很远,现在它就在我的终端里,帮我写代码、改bug,而且是开源的,谁都能用。小米这次真的干了件好事,把顶尖的AI技术免费开放给所有人,这才是科技公司该做的事。